Since the rapid surge in popularity, deep learning has been successfully applied to many areas, such as visual recognition of object categories in images, predicting the toxicity of chemicals, mitosis detection in cancer cells, automated student essay scoring, colorizing artworks and photos, and sketch drawing simplification, and has even surpassed human expert performance on some of the tasks.
Because of the computational intensive nature of deep learning algorithms, traditionally GPUs are used to accelerate both the training and the test phases. FPGAs, with their high flexibility in terms of implementing algorithms, could potentially achieve even higher performance and energy efficiency than GPUs. It came as no surprise that the 25th ACM/SIGDA International Symposium on Field-Programmable Gate Arrays had two sessions focusing on deep learning on FPGAs. In the following posts I will select a few interesting publications from FPGA 2017 and review them here.
Can FPGAs Beat GPUs in Accelerating Next-Generation Deep Neural Networks?
The first paper with the above title that I am going to review is written by Nurvitadhi et al. from Intel. The authors pit their latest Arria 10 and Stratix 10 devices against Titan Xp in the deep learning arena, and show that Stratix 10 has between 10% and 5.4x better performance than Titan Xp in terms of common GEneral Matrix to matrix Multiplication (GEMM) operations, which is at the heart of GPU-based deep learning algorithms.
For the case studies, the authors start by evaluating the two FPGAs and Titan Xp for dense and sparse GEMM with single-precision. Titan Xp with a 11 TFlops theoretical peak performance, has certainly greater throughput than Stratix 10, which is rated 10 TFlops theoretical peak performance. Their positions however reversed as we consider the sparse GEMM, as Titan Xp performed worse than the dense variant, and Stratix 10, with a greater performance at approximately 16.5 tera operations per second, wins the GEMM competition for deep neural networks. Additionally, with the advantage of hardware specialization, Stratix 10 triumphs in terms of GEMMs with reduced precision data-types such as 6-bit integers and binary (1-bit) and ternary (2-bit) representations. The figure below shows the RTL templates Nurvitadhi et al. used to generate FPGA GEMM implementations.
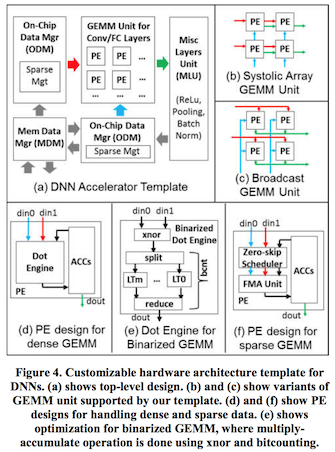
I believe this paper did a good job in justifying FPGAs for deep learning applications. However, there is an important limiting factor to look at for end users, and could be the ultimate reason why many would still consider GPUs in favor. This factor, which the authors from Intel didn’t mention, is the cost. Although Stratix 10 could be 50% faster in sparse GEMM, its development kit is currently priced at $8,000, which is 6.67x that of a Titan Xp. This places Stratix 10 at 2.06 GOP/s/$, whereas Titan Xp is at 9.07 GOP/s/$! Although the cost-effectiveness result favors Stratix 10 in binary neural networks (BNNs), e.g., XNOR-Net , BNNs still cannot match the accuracy of a standard deep neural network in tasks such as ILSVRC. Moreover, the high development cost of FPGA applications further exacerbates the situation.
Personally I don’t think that the low cost-effectiveness of current generation FPGAs would ultimately deter users. On the contrary, because we are still early adopters of deep learning in FPGAs, it foretells the great potential of FPGAs in improving its future viability in deep learning, and FPGAs may even takes the place of GPUs as the main workforce in both inference and training. I have great hopes for my upcoming research direction, and expect fierce competition from other fellow FPGA researchers.